使用 GPU¶
BentoML 提供了一种流线型的方法来部署需要 GPU 资源进行推理任务的服务。
本文档解释了如何配置和分配 GPU,以便使用 BentoML 运行推理。
配置 GPU 资源¶
创建 BentoML 服务时,您需要确保服务实现具有正确的 GPU 配置。
单个设备¶
当单个 GPU 可用时,像 PyTorch 和 TensorFlow 这样的框架默认使用 cuda:0 或 cuda。例如,在 PyTorch 中,要将模型分配给使用 GPU,您使用 .to('cuda:0')。设置 BentoML 服务以使用单个 GPU 的示例
import bentoml
import os
@bentoml.service(resources={"gpu": 1})
class MyService:
# Use a Hugging Face model
model_path = bentoml.models.HuggingFaceModel("org_name/model_id")
# Use a model from the Model Store or BentoCloud
# model_path = bentoml.models.BentoModel("model_name:latest")
def __init__(self):
import torch
# Specify the exact path to the weights file
weights_file = os.path.join(self.model_path, "weight.pt")
self.model = torch.load(weights_file).to('cuda:0')
多个设备¶
在具有多个 GPU 的系统中,每个 GPU 都被分配一个从 0 开始的索引(cuda:0、cuda:1、cuda:2 等)。您可以指定要使用的 GPU 或跨多个 GPU 分布操作。
要使用特定的 GPU
import bentoml
import os
@bentoml.service(resources={"gpu": 2})
class MultiGPUService:
# Load Hugging Face models
model1_path = bentoml.models.HuggingFaceModel("org_name/model1_id")
model2_path = bentoml.models.HuggingFaceModel("org_name/model2_id")
# Use a model from the Model Store or BentoCloud
# model_path = bentoml.models.BentoModel("model_name:latest")
def __init__(self):
import torch
# Specify the exact paths to the weights files
weights_file1 = os.path.join(self.model1_path, "weight1.pt")
weights_file2 = os.path.join(self.model2_path, "weight2.pt")
self.model1 = torch.load(weights_file1).to("cuda:0") # Use the first GPU
self.model2 = torch.load(weights_file2).to("cuda:1") # Use the second GPU
此图解释了不同的模型如何使用分配给它们的 GPU。
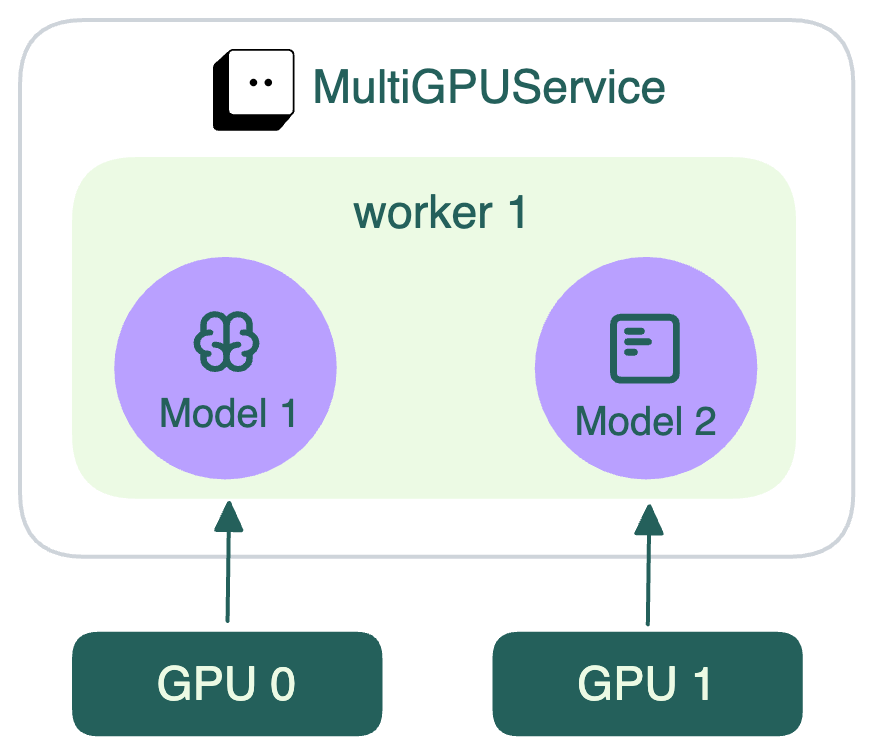
注意
Worker 是实际运行 BentoML 服务中代码逻辑的进程。默认情况下,一个 BentoML 服务有一个 worker。可以设置多个 worker 并为各个 worker 分配特定的 GPU。有关详细信息,请参阅并行处理请求。
如果您想使用多个 GPU 进行分布式操作(同一 worker 使用多个 GPU),PyTorch 和 TensorFlow 提供了不同的方法
PyTorch: DataParallel 和 DistributedDataParallel
TensorFlow: 分布式训练
GPU 部署¶
当使用 PyTorch 或 TensorFlow 在 GPU 上运行模型时,我们建议您通过 pip 直接安装它们及其各自的 CUDA 依赖项。这可确保
最小包大小,因为只安装了所需的组件。
更好的兼容性,因为正确的 CUDA 版本会随着框架自动安装。
对于开发环境,要使用 pip 安装带有相应 CUDA 版本的 PyTorch 或 TensorFlow,请使用以下命令
pip install torch
pip install tensorflow[and-cuda]
构建 Bento 时,只需使用 python_packages 方法添加 PyTorch 和 TensorFlow(或将它们放在单独的 requirements.txt 文件中)。
import bentoml
my_image = bentoml.images.Image(python_version='3.11') \
.python_packages("torch", "tensorflow[and-cuda]")
@bentoml.service(image=my_image)
class MyService:
# Service implementation
要自定义 CUDA 驱动和库的安装,可以在定义运行时规范时使用 base_image 参数以及 system_packages 和 run 方法。
BentoCloud¶
在 BentoCloud 上部署时,在 @bentoml.service 装饰器中通过 gpu 或 gpu_type 指定 resources,以便 BentoCloud 分配必要的 GPU 资源
@bentoml.service(
resources={
"gpu": 1, # The number of allocated GPUs
"gpu_type": "nvidia-l4" # A specific GPU type on BentoCloud
}
)
class MyService:
# Service implementation
要列出您的 BentoCloud 账户中可用的 GPU 类型,运行
$ bentoml deployment list-instance-types
Name Price CPU Memory GPU GPU Type
cpu.1 * 500m 2Gi
cpu.2 * 1000m 2Gi
cpu.4 * 2000m 8Gi
cpu.8 * 4000m 16Gi
gpu.t4.1 * 2000m 8Gi 1 nvidia-tesla-t4
gpu.l4.1 * 4000m 16Gi 1 nvidia-l4
gpu.a100.1 * 6000m 43Gi 1 nvidia-tesla-a100
您的服务准备就绪后,您可以通过运行 bentoml deploy . 将其部署到 BentoCloud。有关详细信息,请参阅创建部署。
Docker¶
您需要安装 NVIDIA Container Toolkit 以便在 Nvidia GPU 上运行 Docker 容器。NVIDIA 提供了安装 Docker CE 和 nvidia-docker 的详细说明。
使用 bentoml containerize 为您的 Bento 构建 Docker 镜像后,您可以按如下方式在所有可用的 GPU 上运行它
docker run --gpus all -p 3000:3000 bento_image:latest
您可以使用 device 选项指定 GPU
docker run --gpus all --device /dev/nvidia0 \
--device /dev/nvidia-uvm --device /dev/nvidia-uvm-tools \
--device /dev/nvidia-modeset --device /dev/nvidiactl <docker-args>
要查看 GPU 使用情况,请使用 nvidia-smi 工具查看 BentoML 服务或 Bento 是否正在使用 GPU。您可以在 BentoML 服务处理请求时在单独的终端中运行它。
# Refresh the output every second
watch -n 1 nvidia-smi
示例输出
Every 1.0s: nvidia-smi ps49pl48tek0: Mon Jun 17 13:09:46 2024
Mon Jun 17 13:09:46 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A100-SXM4-80GB On | 00000000:00:05.0 Off | 0 |
| N/A 30C P0 60W / 400W | 3493MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1813 G /usr/lib/xorg/Xorg 70MiB |
| 0 N/A N/A 1946 G /usr/bin/gnome-shell 78MiB |
| 0 N/A N/A 11197 C /Home/Documents/BentoML/demo/bin/python 3328MiB|
+---------------------------------------------------------------------------------------+
有关更多信息,请参阅Docker 文档。
限制 GPU 可见性¶
通过将 CUDA_VISIBLE_DEVICES 设置为您要使用的 GPU ID,您可以限制 BentoML 仅对您的服务使用特定的 GPU。GPU ID 通常从 0 开始编号。例如
CUDA_VISIBLE_DEVICES=0使只有第一个 GPU 可见。CUDA_VISIBLE_DEVICES=1,2使第二个和第三个 GPU 可见。