BentoML SDK¶
Service 装饰器¶
- bentoml.service(inner: type[T], /) Service[T][source]¶
- bentoml.service(inner: None = None, /, *, image: Image | None = None, envs: list[dict[str, str]] | None = None, labels: dict[str, str] | None = None, **kwargs: Unpack) _ServiceDecorator
将一个类标记为 BentoML 服务。
示例
@service(traffic={“timeout”: 60}) class InferenceService
@api def predict(self, input: str) -> str
return input
Service API¶
- bentoml.api(func: t.Callable[t.Concatenate[t.Any, P], R]) APIMethod[P, R][source]¶
- bentoml.api(*, route: str | None = None, name: str | None = None, input_spec: type[IODescriptor] | None = None, output_spec: type[IODescriptor] | None = None, batchable: bool = False, batch_dim: int | tuple[int, int] = 0, max_batch_size: int = 100, max_latency_ms: int = 60000) t.Callable[[t.Callable[t.Concatenate[t.Any, P], R]], APIMethod[P, R]]
创建一个 BentoML API 方法。此装饰器可以带参数使用,也可以不带参数使用。
- 参数:
func – 要包装的函数。
route – API 的路由。例如:“/predict”
name – API 的名称。
input_spec – API 的输入规范,应是
pydantic.BaseModel的子类。output_spec – API 的输出规范,应是
pydantic.BaseModel的子类。batchable – API 是否可批量处理。
batch_dim – API 的批量维度。
max_batch_size – API 的最大批量大小。
max_latency_ms – API 的最大延迟(毫秒)。
请注意,启用批处理时,batch_dim 可以是元组或单个值。
对于元组 (
input_dim,output_dim)input_dim: 确定在发送进行处理之前,输入数组应沿哪个维度进行批处理(或堆叠)。例如,如果您正在处理 2-D 数组,并且input_dim设置为 0,BentoML 将沿第一个维度堆叠这些数组。这意味着如果您有两个尺寸为 5x2 和 10x2 的 2-D 输入数组,指定input_dim为 0 会将它们组合成一个 15x2 的数组进行处理。output_dim: 推理完成后,输出数组需要按原始批量大小拆分回去。output_dim指示应沿哪个维度拆分输出数组。在上面的示例中,如果推理过程返回一个 15x2 的数组,并且output_dim设置为 0,BentoML 将根据记录的输入批量边界,将此数组拆分回原始大小的 5x2 和 10x2。这确保了每个请求者接收到与他们输入相对应的正确部分输出。
如果您为
batch_dim指定单个值,则此值将同时应用于input_dim和output_dim。换句话说,用于批处理输入和拆分输出的是同一个维度。
batch_dim 的图像说明
此图解说明了在处理二维数组时 batch_dim 的概念。
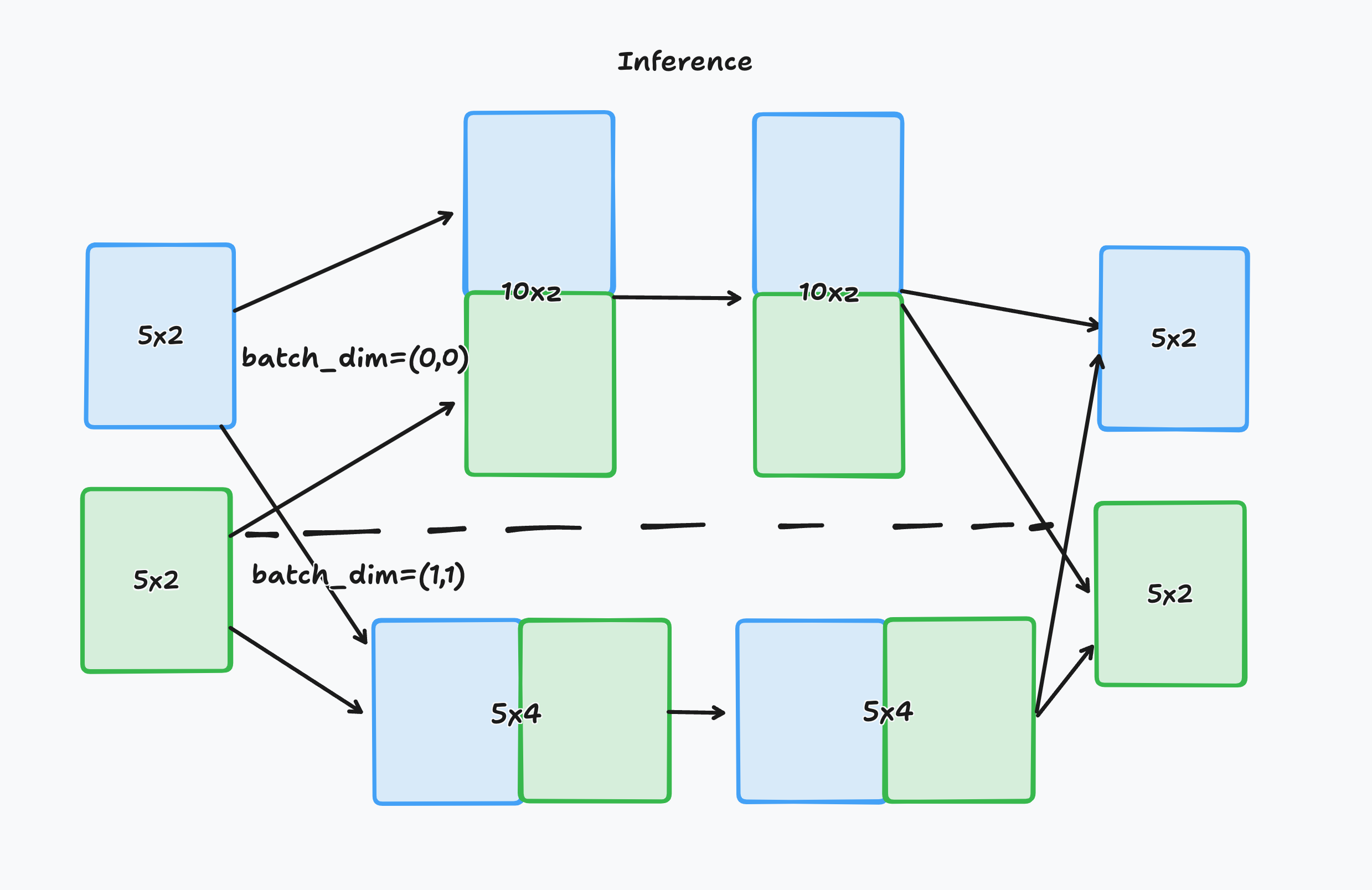
左侧有两个尺寸为 5x2 的二维数组,分别由蓝色和绿色框表示。箭头显示了这些数组根据 batch_dim 配置可以采用的两种不同路径。
顶部路径配置为
batch_dim=(0,0)。这意味着批处理沿第一维度(行数)进行。两个数组堆叠在一起,形成一个尺寸为 10x2 的新组合数组,用于推理。推理后,结果被拆分回两个独立的 5x2 数组。底部路径配置为
batch_dim=(1,1)。这意味着批处理沿第二维度(列数)进行。两个数组并排连接,形成一个尺寸为 5x4 的更大数组,由模型处理。推理后,输出数组被拆分回原始维度,形成两个独立的 5x2 数组。
- bentoml.task(func: t.Callable[t.Concatenate[t.Any, P], R]) APIMethod[P, R][source]¶
- bentoml.task(*, route: str | None = None, name: str | None = None, input_spec: type[IODescriptor] | None = None, output_spec: type[IODescriptor] | None = None, batchable: bool = False, batch_dim: int | tuple[int, int] = 0, max_batch_size: int = 100, max_latency_ms: int = 60000) t.Callable[[t.Callable[t.Concatenate[t.Any, P], R]], APIMethod[P, R]]
将方法标记为 BentoML 异步任务。此装饰器可以带参数使用,也可以不带参数使用。
- 参数:
func – 要包装的函数。
route – API 的路由。例如:“/predict”
name – API 的名称。
input_spec – API 的输入规范,应是
pydantic.BaseModel的子类。output_spec – API 的输出规范,应是
pydantic.BaseModel的子类。batchable – API 是否可批量处理。
batch_dim – API 的批量维度。
max_batch_size – API 的最大批量大小。
max_latency_ms – API 的最大延迟(毫秒)。
bentoml.depends¶
- bentoml.depends(*, url: str | None = None, deployment: str | None = None, cluster: str | None = None) Dependency[None][source]¶
- bentoml.depends(on: Service[T], *, url: str | None = None, deployment: str | None = None, cluster: str | None = None) Dependency[T]
创建对其他服务或部署的依赖
- 参数:
on – Service[T] | None: 依赖的服务。
url – str | None: 依赖服务的 URL。
deployment – str | None: 依赖服务的部署。
cluster – str | None: 依赖服务的集群。
示例
@bentoml.service class MyService: # depends on a service svc_a = bentoml.depends(SVC_A) # depends on a deployment svc_b = bentoml.depends(deployment="ci-iris") # depends on a remote service with url svc_c = bentoml.depends(url="http://192.168.1.1:3000") # For the latter two cases, the service can be given to provide more accurate types: svc_d = bentoml.depends(url="http://192.168.1.1:3000", on=SVC_D)
bentoml.validators¶
- class bentoml.validators.FileSchema(format: str = 'binary', content_type: str | None = None)[source]¶
Bases:
object
- class bentoml.validators.TensorSchema(format: TensorFormat, dtype: t.Optional[str] = None, shape: t.Optional[t.Tuple[int, ...]] = None)[source]¶
Bases:
object- format: TensorFormat¶
- class bentoml.validators.DataframeSchema(orient: str = 'records', columns=None)[source]¶
Bases:
object- validate(obj: t.Any) pd.DataFrame¶