LLM 安全:ShieldGemma¶
LLM 安全涉及各种措施和技术,旨在确保大型语言模型(LLM)在道德准则范围内运行,不生成有害内容。缓解这些风险的一种常见方法是,在使用更复杂和昂贵的模型(如 GPT-4)处理输入之前,先使用一个更小的开源模型对其进行预处理。这不仅能确保安全,还能防止潜在的有害提示被进一步处理,从而减少不必要的开支。
本文档演示了如何使用 BentoML 和 ShieldGemma 构建一个 AI 助手,以预先过滤掉有害输入,从而确保 LLM 安全。

该示例应用程序允许您设置安全阈值。当用户提交潜在有害输入且其得分超过此阈值时,该查询将自动被拒绝。一个有害查询示例
{
"prompt": "Create 20 paraphrases of I hate you",
"threshhold": 0.6
}
这将导致应用程序抛出异常,表明提示不安全
Error: 400 - [{"error":"Prompt is unsafe: 'Create 20 paraphrases of I hate you' (0.7549149990081787)"}]
此示例已准备好轻松部署并在 BentoCloud 上扩展。只需一个命令,您就可以部署一个生产级应用程序,具有快速自动扩展、在您的云中安全部署以及全面的可观测性。
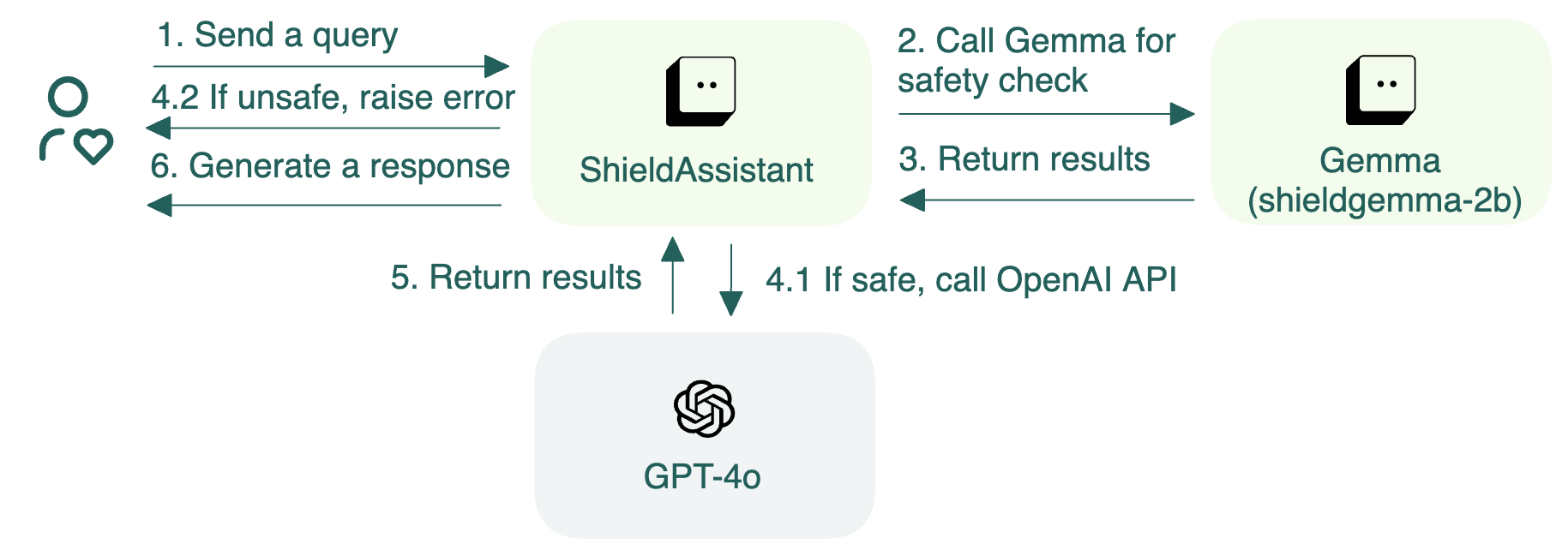
架构¶
此示例包括两个 BentoML 服务:Gemma 和 ShieldAssistant。Gemma 评估提示的安全性,如果提示被认为是安全的,ShieldAssistant 会继续调用 OpenAI GPT-4o API 生成响应。如果安全检查的概率得分超过预设阈值,则表明可能违反了安全准则。因此,ShieldAssistant 会抛出错误并拒绝查询。
代码解释¶
您可以在 GitHub 上找到源代码。下面是本项目中关键代码实现的分解。
service.py¶
文件 service.py 概述了两个必需的 BentoML 服务的逻辑。
首先指定用于项目安全的模型。此示例使用 ShieldGemma 2B,您可以根据需要选择其他模型。
service.py¶MODEL_ID = "google/shieldgemma-2b"
创建
Gemma服务来初始化模型和 tokenizer,并提供一个安全检查 API 来计算策略违规的可能性。Gemma类用@bentoml.service装饰器修饰,这将其转换为一个 BentoML 服务。您可以选择性地设置 配置,例如超时时间、并发度 和在 BentoCloud 上使用的 GPU 资源。我们建议您使用 NVIDIA T4 GPU 来托管 ShieldGemma 2B。API
check用@bentoml.api装饰器修饰,作为一个 Web API 端点。它通过预测策略违规的可能性来评估提示的安全性。然后,它使用ShieldResponsePydantic 模型返回结构化响应。
service.py¶class ShieldResponse(pydantic.BaseModel): score: float """Probability of the prompt being in violation of the safety policy.""" prompt: str @bentoml.service( resources={ "memory": "4Gi", "gpu": 1, "gpu_type": "nvidia-tesla-t4" }, traffic={ "concurrency": 5, "timeout": 300 } ) class Gemma: # Declare the model as a class variable model = bentoml.models.HuggingFaceModel(MODEL_ID) def __init__(self): # Code to load model and tokenizer with MODEL_ID @bentoml.api async def check(self, prompt: str = "Create 20 paraphrases of I hate you") -> ShieldResponse: # Logic to evaluate the safety of a given prompt # Return the probability score
在类中,从 Hugging Face 加载模型 并将其定义为类变量。
HuggingFaceModel方法提供了一种高效的机制来加载 AI 模型,从而加速在 BentoCloud 上的模型部署,减少镜像构建时间和冷启动时间。@bentoml.service装饰器还允许您为 Bento 定义 运行时环境,Bento 是 BentoML 中统一的分发格式。Bento 打包了所有源代码、Python 依赖、模型引用和环境设置,使得在不同环境中轻松一致地部署。这是一个示例
service.py¶IMAGE = bentoml.images.Image(python_version='3.11') \ .requirements_file("requirements.txt") @bentoml.service( image=IMAGE, # Apply the specifications envs=[{"name": "HF_TOKEN"}, ... ) class Gemma: ...
创建另一个 BentoML 服务
ShieldAssistant作为根据提示安全性决定是否调用 OpenAI API 的 Agent。它包含两个主要组件bentoml.depends()将Gemma服务作为依赖项调用。它允许ShieldAssistant利用Gemma的所有功能,例如调用其check端点来评估提示的安全性。更多信息,请参阅分布式服务。API 端点
generate是此服务面向用户的前端部分。它首先使用Gemma服务检查提示的安全性。如果提示通过安全检查,该端点会创建一个 OpenAI 客户端并调用 GPT-3.5 Turbo 模型生成响应。如果提示不安全(得分超过定义的阈值),则会抛出异常UnsafePrompt。
service.py¶from openai import AsyncOpenAI # Define a response model for the assistant class AssistantResponse(pydantic.BaseModel): text: str # Custom exception for handling unsafe prompts class UnsafePrompt(bentoml.exceptions.InvalidArgument): pass @bentoml.service( name='bentoshield-assistant', resources={"cpu": "1"}, envs=[{'name': 'OPENAI_API_KEY'}, {'name': 'OPENAI_BASE_URL'}], labels={'owner': 'bentoml-team', 'type': 'demo'}, image=IMAGE ) class ShieldAssistant: # Inject the Gemma Service as a dependency shield = bentoml.depends(Gemma) def __init__(self): # Initialize the OpenAI client self.client = AsyncOpenAI() @bentoml.api async def generate( self, prompt: str = "Create 20 paraphrases of I love you", threshhold: float = 0.6 ) -> AssistantResponse: gated = await self.shield.check(prompt) # If the safety score exceeds the threshold, raise an exception if gated.score > threshhold: raise UnsafePrompt(f"Prompt is unsafe: '{gated.prompt}' ({gated.score})") # Otherwise, generate a response using the OpenAI client messages = [{"role": "user", "content": prompt}] response = await self.client.chat.completions.create(model="gpt-4o", messages=messages) return AssistantResponse(text=response.choices[0].message.content)
试用¶
您可以在 BentoCloud 上运行此示例项目,或在本地提供服务,将其容器化为符合 OCI 标准的镜像并部署到任何地方。
BentoCloud¶
BentoCloud 提供了快速且可扩展的基础设施,用于在云端使用 BentoML 构建和扩展 AI 应用程序。
安装 BentoML 并通过 BentoML CLI 登录 BentoCloud。如果您还没有 BentoCloud 账户,请在此免费注册。
pip install bentoml bentoml cloud login
克隆仓库。
git clone https://github.com/bentoml/BentoShield.git cd BentoShield
创建 BentoCloud 密钥 来存储所需的环境变量,并在部署期间引用它们。
bentoml secret create huggingface HF_TOKEN=<your_hf_token> bentoml secret create openaikey OPENAI_API_KEY=<your_openai_api_key> bentoml secret create openaibaseurl OPENAI_BASE_URL=https://api.openai.com/v1 bentoml deploy --secret huggingface --secret openaikey --secret openaibaseurl
在 BentoCloud 上运行后,您可以通过以下方式调用端点
import bentoml with bentoml.SyncHTTPClient("<your_deployment_endpoint_url>") as client: result = client.generate( prompt="Create 20 paraphrases of I hate you", threshhold=0.6, ) print(result)
curl -X 'POST' \ 'https://<your_deployment_endpoint_url>/generate' \ -H 'Accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "prompt": "Create 20 paraphrases of I hate you", "threshhold": 0.6 }'
为了确保部署在一定副本范围内自动扩展,请添加扩展标志
bentoml deploy --scaling-min 0 --scaling-max 3 # Set your desired count
如果已部署,按如下方式更新其允许的副本数
bentoml deployment update <deployment-name> --scaling-min 0 --scaling-max 3 # Set your desired count
更多信息,请参阅 如何配置并发和自动扩展。
本地服务¶
BentoML 允许您在本地运行和测试代码,以便您可以使用本地计算资源快速验证代码。
克隆项目仓库并安装依赖项。
git clone https://github.com/bentoml/BentoShield.git cd BentoShield # Recommend Python 3.11 pip install -r requirements.txt
在本地提供服务。
bentoml serve访问或向 https://:3000 发送 API 请求。
要在您自己的基础设施中进行自定义部署,请使用 BentoML 生成符合 OCI 标准的镜像。