并行处理请求¶
BentoML worker 增强了机器学习模型的并行处理能力。在其底层,一个 BentoML 服务 (Service) 中有一个或多个 worker。它们是实际运行服务内代码逻辑的进程。这种设计利用了底层硬件的并行性,无论是多核 CPU 还是多设备 GPU。
本文档解释了如何为不同的用例配置和分配 worker。
配置 worker¶
当您定义一个 BentoML 服务 (Service) 时,使用 workers 参数来设置 worker 的数量。例如,设置 workers=4 会启动四个服务 worker 实例,每个实例都在自己的进程中运行。每个 worker 都是同质的,这意味着它们执行相同的任务。
@bentoml.service(
workers=4,
)
class MyService:
# Service implementation
worker 的数量不一定等同于 BentoML 服务 (Service) 可以并行处理的并发请求数量。通过 自适应批处理 和连续批处理等优化,每个 worker 可以潜在地同时处理许多请求,从而提高服务的吞吐量。要指定服务(即服务内的所有 worker)的理想并发请求数量,您可以配置并发数 (concurrency)。
用例¶
Worker 允许 BentoML 服务 (Service) 有效地利用底层硬件加速器,如 CPU 和 GPU,确保最佳性能和资源利用率。
BentoML 中的默认 worker 数量设置为 1。但是,根据您的计算工作负载和硬件配置,您可能需要调整此数量。
CPU 工作负载¶
Python 进程受全局解释器锁 (GIL) 的限制,这是一种阻止多个原生线程同时执行 Python 代码的机制。这意味着在多线程 Python 程序中,即使它在多核处理器上运行,一次也只能有一个线程执行 Python 代码。这限制了 CPU 密集型 Python 程序的性能,使其无法通过多线程充分利用多核 CPU 的计算能力。
为了避免这种情况并充分利用多核 CPU,您可以启动多个 worker。但是,请注意内存影响,因为每个 worker 都会将模型副本加载到内存中。请确保您的机器内存能够支持所有 worker 的累计内存需求。
您可以通过将 workers 设置为 cpu_count 来根据可用的 CPU 核数设置 worker 进程的数量。
@bentoml.service(workers="cpu_count")
class MyService:
# Service implementation
GPU 工作负载¶
在多设备 GPU 的场景中,将特定 GPU 分配给不同的 worker 允许每个 worker 独立处理任务。这可以最大化并行处理,提高吞吐量,并缩短整体推理时间。
您使用 worker_index 来表示一个 worker 实例,它是 BentoML 服务 (Service) 中每个 worker 进程的唯一标识符,从 0 开始。此索引主要用于在多个 worker 之间分配 GPU。一个常见的用例是每个 CUDA 设备加载一个模型,以确保每个 GPU 都得到有效利用,并防止模型之间的资源争用。
这是一个例子
import bentoml
@bentoml.service(
resources={"gpu": 2},
workers=2
)
class MyService:
def __init__(self):
import torch
cuda = torch.device(f"cuda:{bentoml.server_context.worker_index-1}")
model = models.resnet18(pretrained=True)
model.to(cuda)
该服务 (Service) 通过创建 torch.device 对象来动态确定模型使用的 GPU 设备。设备 ID 由 bentoml.server_context.worker_index - 1 设置,以便为每个 worker 进程分配一个特定的 GPU。Worker 1 (worker_index = 1) 使用 GPU 0,Worker 2 (worker_index = 2) 使用 GPU 1。详情见下图。
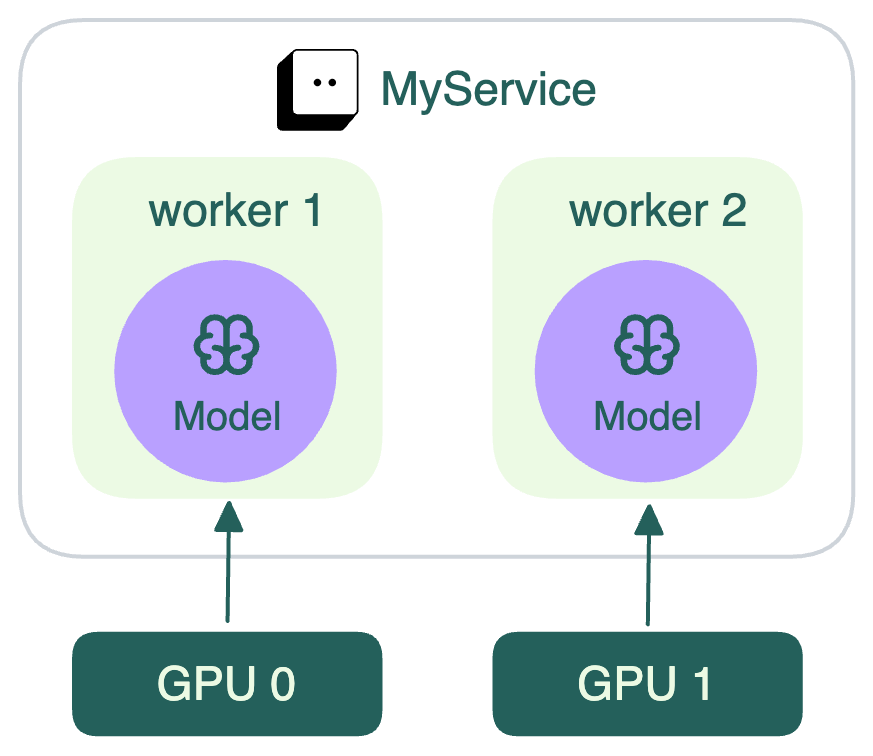
在确定为每个 worker 分配哪个设备 ID 来执行将模型加载到 GPU 等任务时,这种从 1 开始索引的方法意味着您需要从 worker_index 中减去 1 才能获得从 0 开始的设备 ID。这是因为 GPU 等硬件设备通常从 0 开始索引。更多信息,请参阅使用 GPU。
如果您想使用多个 GPU 进行分布式操作(同一 worker 使用多个 GPU),PyTorch 和 TensorFlow 提供了不同的方法
PyTorch: DataParallel 和 DistributedDataParallel
TensorFlow: 分布式训练