Agent: LangGraph¶
LangGraph 是一个开源库,用于构建带有 LLM 的有状态、多 actor 应用程序。它允许您定义多种控制流来创建 Agent 和多 Agent 工作流。
本文档演示了如何使用 BentoML 服务化 LangGraph Agent 应用程序。

当使用的 LLM 缺乏必要知识时,示例 LangGraph Agent 会调用 DuckDuckGo 来检索最新信息。例如
{
"query": "Who won the gold medal at the men's 100 metres event at the 2024 Summer Olympic?"
}
示例输出
Noah Lyles (USA) won the gold medal at the men's 100 metres event at the 2024 Summer Olympic Games. He won by five-thousands of a second over Jamaica's Kishane Thompson.
此示例已准备好在 BentoCloud 上轻松部署和扩展。您可以使用外部 LLM API,或者将开源 LLM 与 LangGraph Agent 一起部署。只需一个命令,您就可以获得一个生产级应用程序,它具有快速自动扩缩容、在您的云中安全部署以及全面的可观测性。
架构¶
该项目包含两个主要组件:一个 BentoML Service,用于将 LangGraph Agent 作为 REST API 进行服务化,以及一个用于生成文本的 LLM。LLM 可以是像 Claude 3.5 Sonnet 这样的外部 API,也可以是通过 BentoML 服务化的开源模型(在本例中是 Ministral-8B-Instruct-2410)。
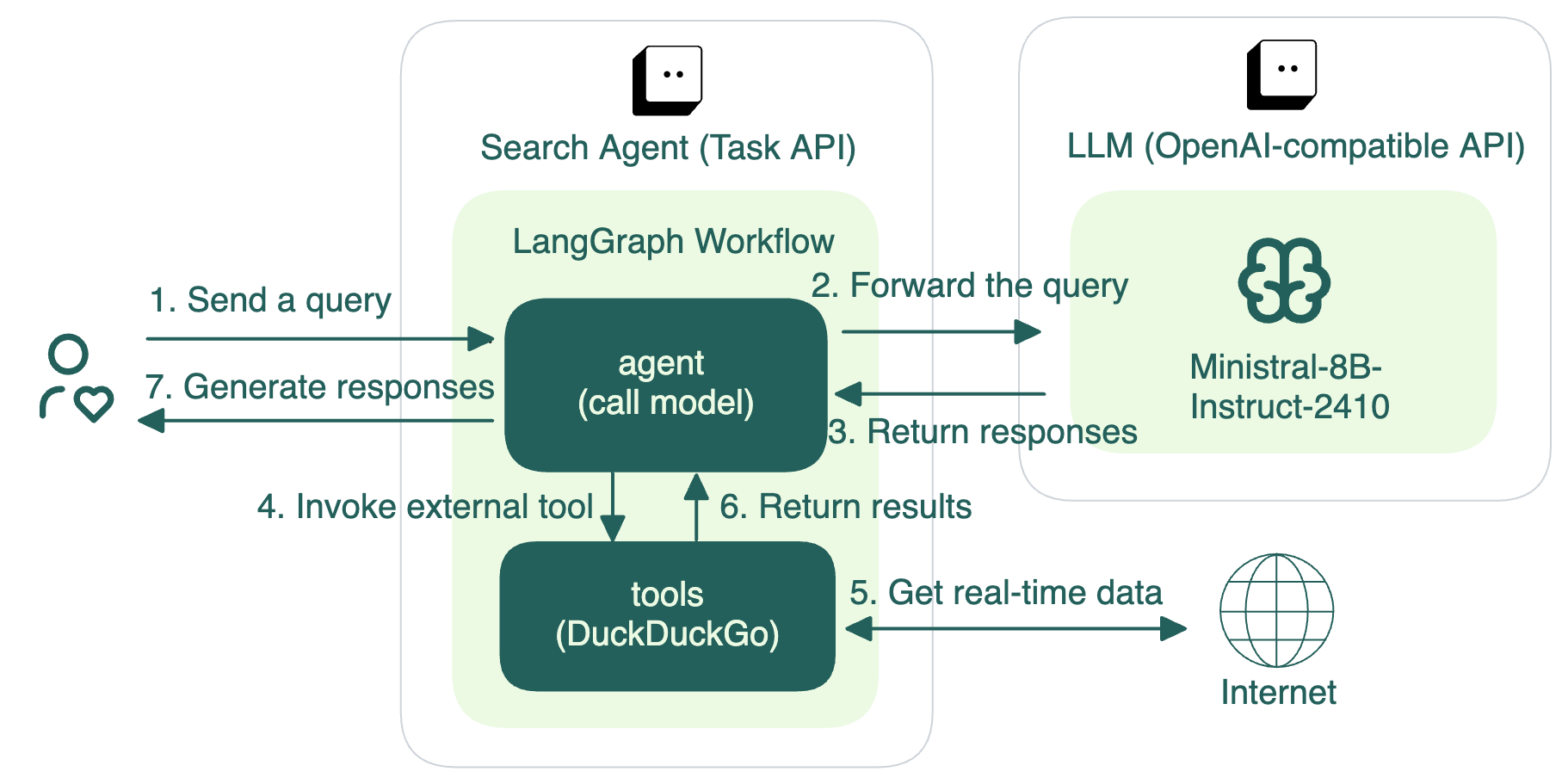
用户提交查询后,会通过 LangGraph Agent 进行处理,其中包含
一个 Agent 节点,它使用 LLM 来理解查询并决定操作。
一个 Tools 节点,如果需要,可以调用外部工具。
在此示例中,如果 LLM 需要额外信息,Tools 节点会调用 DuckDuckGo 在互联网上搜索必要数据。然后 DuckDuckGo 将搜索结果返回给 Agent,Agent 汇总信息并向用户提供最终响应。
代码解释¶
本示例包含以下两个子项目,演示了如何使用不同的 LLM
langgraph-anthropic 使用 Claude 3.5 Sonnet
langgraph-mistral 使用 Ministral-8B-Instruct-2410
这两个子项目遵循相同的逻辑实现 LangGraph Agent。本文档解释了 langgraph-mistral 中的关键代码实现。
service.py¶
service.py 文件定义了一个 BentoML Service
LLM,用于服务化 Ministral-8B-Instruct-2410 模型。如果需要,您可以通过更改model值来切换到不同的模型。service.py¶ENGINE_CONFIG = { "model": "mistralai/Ministral-8B-Instruct-2410", "tokenizer_mode": "mistral", "max_model_len": 4096, "enable_prefix_caching": False, } @bentoml.service class LLM: model_id = ENGINE_CONFIG["model"] ...
LLM提供与 OpenAI 兼容的 API,并使用 vLLM 作为推理后端。它是一个依赖的 BentoML Service,可以由 LangGraph Agent 调用。有关代码解释的更多信息,请参见LLM 推理: vLLM。创建另一个 Service
SearchAgentService来封装 LangGraph Agent。您可以选择设置配置,例如Worker和并发数。service.py¶@bentoml.service( workers=2, resources={ "cpu": "2000m" }, traffic={ "concurrency": 16, "external_queue": True } ) class SearchAgentService: ...
为了在 BentoCloud 上部署,我们建议您设置
concurrency并启用external_queue。Concurrency指的是 Service 可以同时处理的请求数量。启用external_queue后,如果应用程序同时收到超过 16 个请求,额外的请求将被放入外部队列中。当前请求完成后,这些请求将被处理,这使您能够处理流量峰值而不会丢失请求。定义运行时环境以创建 Bento,这是 BentoML 中的统一分发格式。Bento 包含所有源代码、Python 依赖项、模型引用和环境设置,使其易于在不同环境中一致地部署。
以下是一个示例
service.py¶my_image = bentoml.images.Image(python_version='3.11', lock_python_packages=False) \ .requirements_file("requirements.txt") @bentoml.service( image=my_image, # Apply the specifications envs=[{"name": "HF_TOKEN"}], ... ) class SearchAgentService: ...
使用
bentoml.depends()函数调用LLMService,这使得SearchAgentService可以利用其所有功能,例如调用其与 OpenAI 兼容的 API 端点。service.py¶from langchain_openai import ChatOpenAI ... class SearchAgentService: # Call the LLM Service llm_service = bentoml.depends(LLM) def __init__(self): tools = [search] self.tools = ToolNode(tools) self.model = ChatOpenAI( model=LLM.inner.model_id, openai_api_key="N/A", openai_api_base=f"{self.llm_service.client_url}/v1", temperature=0, verbose=True, http_client=self.llm_service.to_sync.client, ).bind_tools(tools) # Logic to create LangGraph graph and add nodes & edges ...
注入
LLMService 后,使用langchain_openai中的 ChatOpenAI API 来配置与其交互的接口。由于LLMService 提供与 OpenAI 兼容的 API 端点,您可以使用其 HTTP 客户端 (to_sync.client) 和客户端 URL (client_url) 轻松构建一个 OpenAI 客户端进行交互。之后,定义使用该模型的 LangGraph 工作流。LangGraph Agent 将调用此模型,并使用节点和边构建其流程,将 LLM 的输出与系统的其余部分连接起来。有关实现 LangGraph 工作流的详细解释,请参阅LangGraph 文档。
使用
@bentoml.task将 BentoML 任务端点invoke定义为异步处理 LangGraph 工作流。它是一个支持长时间运行操作的后台任务。这确保了涉及外部工具的复杂 LangGraph 工作流可以在不超时的情况下完成。将用户的查询发送到 LangGraph Agent 后,该任务会检索最终状态并将结果返回给用户。
service.py¶# Define a task endpoint @bentoml.task async def invoke( self, input_query: str = "What is the weather in San Francisco today?", ) -> str: try: # Invoke the LangGraph agent workflow asynchronously final_state = await self.app.ainvoke({"messages": [HumanMessage(content=input_query)]}) # Return the final message from the workflow return final_state["messages"][-1].content # Handle errors that may occur during model invocation except OpenAIError as e: logger.error(f"An error occurred: {e}") logger.error(traceback.format_exc()) return "I'm sorry, but I encountered an error while processing your request. Please try again later."
提示
我们建议您为此 LangGraph Agent 应用程序使用任务端点。这是因为 LangGraph Agent 通常使用多步骤工作流,包括查询 LLM 和调用外部工具。此类工作流可能比典型的 HTTP 请求周期更长。如果同步处理,您的应用程序可能会面临请求超时,尤其是在高流量下。BentoML 任务端点通过将长时间运行的任务卸载到后台来解决此问题。您可以发送查询并在稍后检查结果,确保推理过程顺畅无超时。
可以选择添加流式 API 以实时发送中间结果。使用
@bentoml.api将stream函数转换为 API 端点,并调用astream_events以流式传输 LangGraph Agent 生成的事件。service.py¶@bentoml.api async def stream( self, input_query: str = "What is the weather in San Francisco today?", ) -> typing.AsyncGenerator[str, None]: # Loop through the events generated by the LangGraph workflow async for event in self.app.astream_events({"messages": [HumanMessage(content=input_query)]}, version="v2"): yield str(event) + "\n"
有关
astream_eventsAPI 的更多信息,请参阅LangGraph 文档。
试用¶
您可以在 BentoCloud 上运行此示例项目,或在本地服务化、将其容器化为 OCI 兼容镜像并在任何地方部署。
BentoCloud¶
BentoCloud 提供快速可扩展的基础设施,用于在云中构建和扩展使用 BentoML 的 AI 应用程序。
安装 BentoML 并通过 BentoML CLI 登录 BentoCloud。如果您没有 BentoCloud 账户,请在此免费注册。
pip install bentoml bentoml cloud login
克隆仓库并选择所需的项目进行部署。我们建议您创建一个 BentoCloud 密钥来存储所需的环境变量。
git clone https://github.com/bentoml/BentoLangGraph.git # Use Ministral-8B-Instruct-2410 cd BentoLangGraph/langgraph-mistral bentoml secret create huggingface HF_TOKEN=$HF_TOKEN bentoml deploy --secret huggingface # Use Claude 3.5 Sonnet cd BentoLangGraph/langgraph-anthropic bentoml secret create anthropic ANTHROPIC_API_KEY=$ANTHROPIC_API_KEY bentoml deploy --secret anthropic
在 BentoCloud 上启动并运行后,您可以通过以下方式调用端点
import bentoml with bentoml.SyncHTTPClient("<your_deployment_endpoint_url>") as client: result = client.invoke( input_query="Who won the gold medal at the men's 100 metres event at the 2024 Summer Olympic?", ) print(result)
curl -s -X POST \ 'https://<your_deployment_endpoint_url>/invoke' \ -H 'Content-Type: application/json' \ -d '{ "input_query": "Who won the gold medal at the men's 100 metres event at the 2024 Summer Olympic?" }'
为确保 Deployment 在一定副本范围内自动扩缩容,添加扩缩容标志
bentoml deploy --secret huggingface --scaling-min 0 --scaling-max 3 # Set your desired count
如果已部署,按如下方式更新其允许的副本数
bentoml deployment update <deployment-name> --scaling-min 0 --scaling-max 3 # Set your desired count
更多信息,请参见如何配置并发和自动扩缩容。
本地服务化¶
BentoML 允许您在本地运行和测试代码,以便您可以使用本地计算资源快速验证代码。
克隆仓库并选择您所需的项目。
git clone https://github.com/bentoml/BentoLangGraph.git # Recommend Python 3.11 # Use Ministral-8B-Instruct-2410 cd BentoLangGraph/langgraph-mistral pip install -r requirements.txt export HF_TOKEN=<your-hf-token> # Use Claude 3.5 Sonnet cd BentoLangGraph/langgraph-anthropic pip install -r requirements.txt export ANTHROPIC_API_KEY=<your-anthropic-api-key>
在本地服务化。
bentoml serve注意
要在本地使用 Ministral-8B-Instruct-2410 运行此项目,您需要一块至少具有 16G 显存的 NVIDIA GPU。
访问或向 https://:3000 发送 API 请求。
要在您自己的基础设施中进行自定义部署,请使用 BentoML 生成一个 OCI 兼容的镜像。