自适应批处理¶
许多模型在批量处理请求时可以实现更高的吞吐量、更好的资源利用率和更低的延迟。BentoML 支持自适应批处理,这是一种动态请求分发机制,它智能地将多个请求分组以实现更高效的处理。它根据实时流量模式持续调整批处理大小和窗口。这确保了最佳性能,因为它在低流量期间提供快速响应,并在高负载下最大化资源利用率。
注意
批处理意味着将多个输入分组到一个批次中进行处理。它包括两个主要概念
批处理窗口:服务在处理请求之前等待将请求累积到批处理中的最长时间。
批处理大小:批处理中的最大请求数。
架构¶
自适应批处理是在服务器端实现的。与客户端批处理相比,这具有优势,因为它简化了客户端逻辑,并且由于流量大,通常效率更高。
具体来说,BentoML Service 中有一个调度器,负责将请求收集到批次中,直到满足批处理窗口或批处理大小的条件,此时将批次发送到模型进行推理。
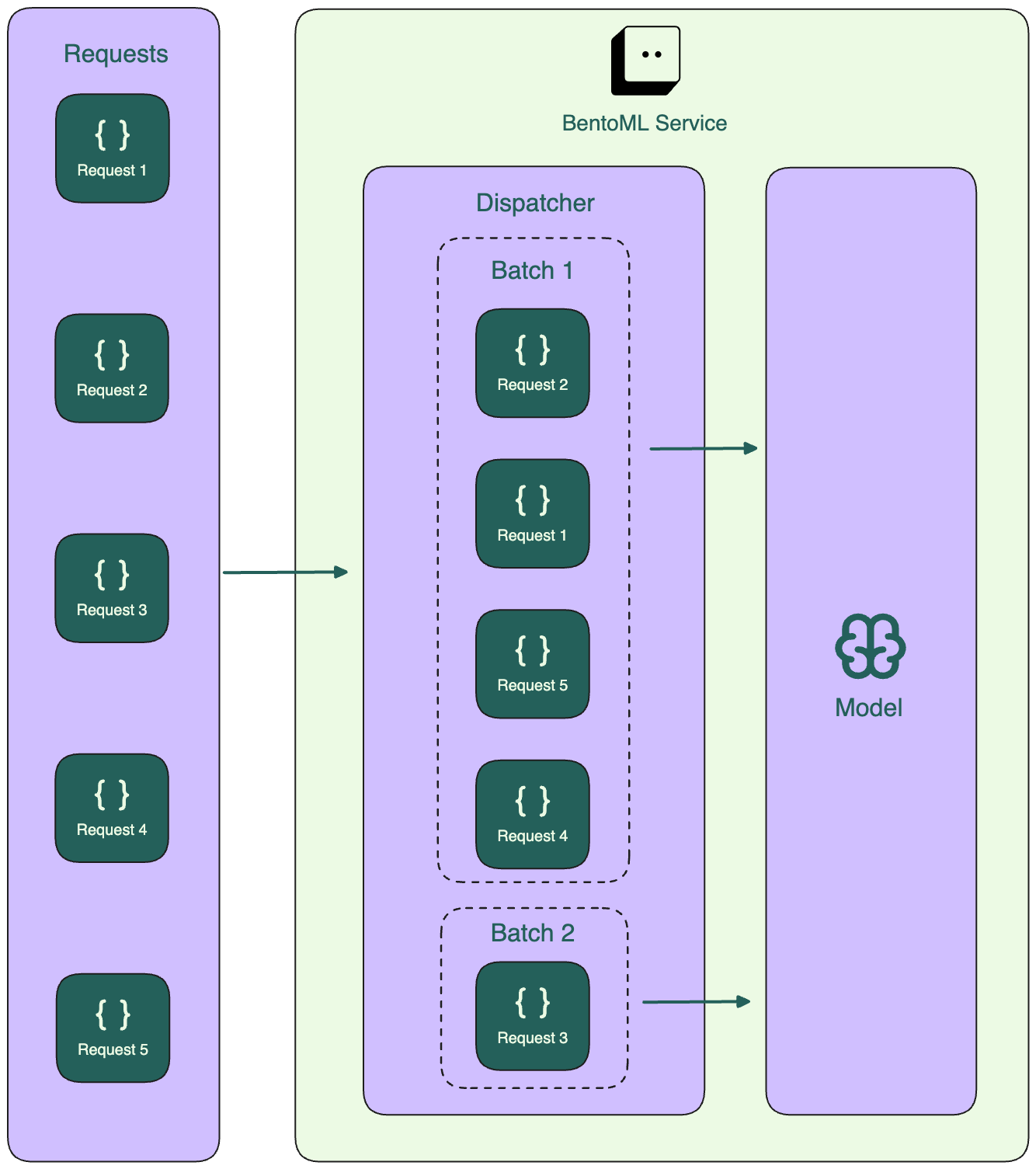
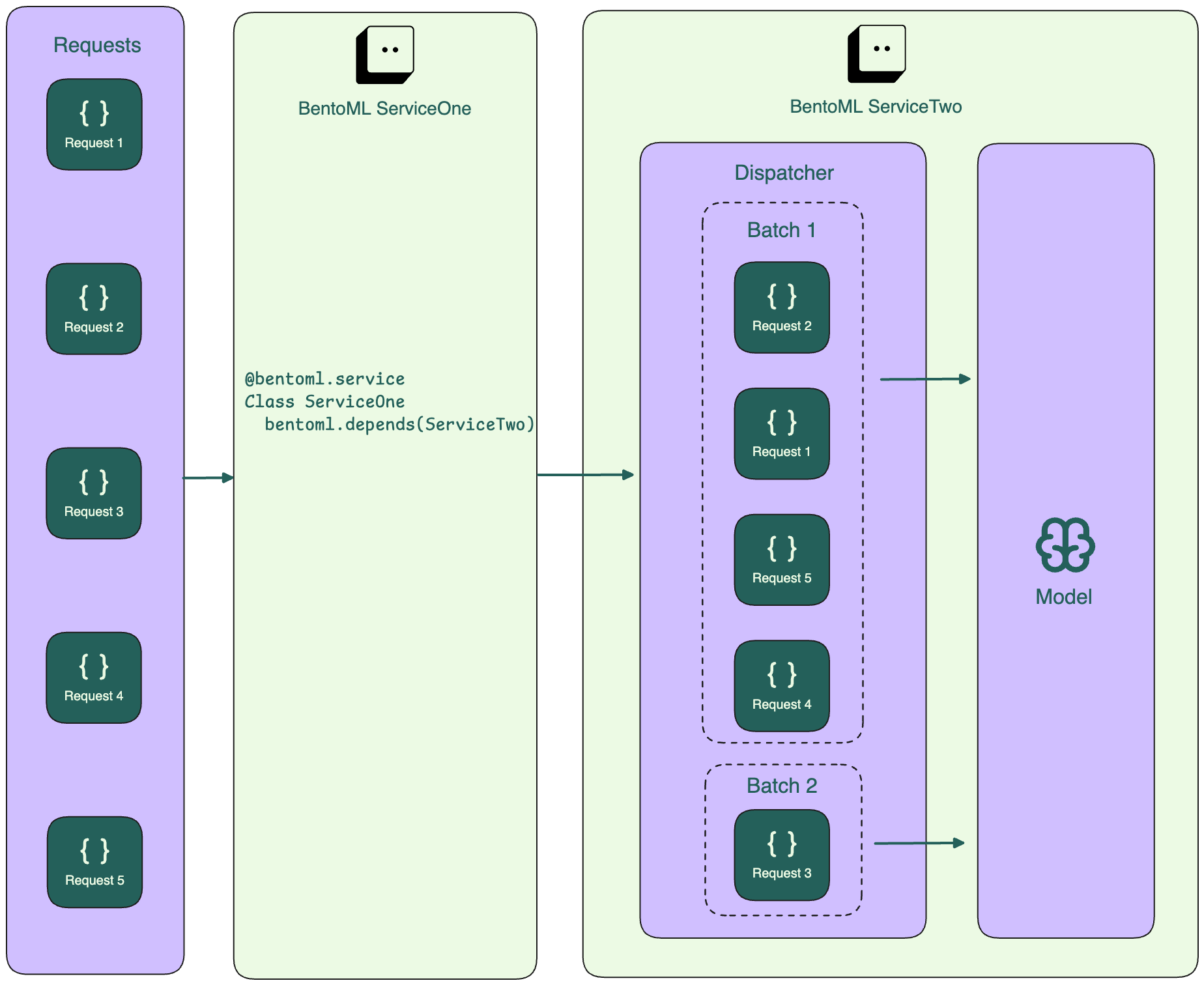
对于多个服务,负责运行模型推理的服务(下图中的 ServiceTwo)从中间服务(ServiceOne)收集请求,并根据最佳延迟形成批次。
注意
函数 bentoml.depends() 允许一个 Service 使用另一个 Service 的功能。详情请参见 运行分布式服务。
自适应批处理算法根据最近的请求模式趋势和处理时间持续学习和调整批处理参数。这意味着在高流量时,批次可能更大且处理更频繁,而在流量较少时,BentoML 将优先考虑降低延迟,即使这意味着更小的批处理大小。
不保证批处理中请求的顺序。
配置自适应批处理¶
默认情况下,自适应批处理是禁用的。使用 @bentoml.api 装饰器启用它并配置 API 端点的批处理行为。
这里是为 Hello world 中的摘要服务启用批处理的示例。
from __future__ import annotations
import bentoml
from typing import List
from transformers import pipeline
@bentoml.service
class Summarization:
def __init__(self) -> None:
self.pipeline = pipeline('summarization')
# Set `batchable` to True to enable batching
@bentoml.api(batchable=True)
def summarize(self, texts: List[str]) -> List[str]:
results = self.pipeline(texts)
return [item['summary_text'] for item in results]
注意可批处理的 API
应是能封装多个独立请求的类型,例如
typing.List[str]或numpy.ndarray。除
bentoml.Context外,只接受一个参数。
您可以通过 BentoML 客户端 调用可批处理的端点
import bentoml
from typing import List
client = bentoml.SyncHTTPClient("https://:3000")
# Specify the texts to summarize
texts: List[str] = [
"Paragraph one to summarize",
"Paragraph two to summarize",
"Paragraph three to summarize"
]
# Call the exposed API
response = client.summarize(texts=texts)
print(f"Summarized results: {response}")
自适应批处理的其他可用参数
batch_dim:输入和输出的批处理维度,可以是元组或单个值。更多信息请参见 Service API。max_batch_size:可以分组到单个批次中的请求数量上限。根据可用资源(如内存或 GPU)设置此参数,以避免系统过载。max_latency_ms:端到端批处理延迟的上限(以毫秒为单位)。调度器将通过预测处理批次所需的时间来遵守此值。
当您指定 max_batch_size 和 max_latency_ms 参数时,即使 BentoML 根据自适应批处理算法动态调整批处理大小和处理间隔,它也会确保遵守这些约束。该算法的主要目标是优化吞吐量(通过将请求组合成批次)和延迟(通过确保在可接受的时间范围内处理请求)。然而,它在这些参数设置的范围内运行。
注意
当在一个 Service 中使用同步端点调用另一个 Service 中的可批处理端点时,它一次只发送一个请求,并在发送下一个请求之前等待响应。这是由于同步端点的默认并发为 1。要启用并发请求并允许批处理,请在 @bentoml.service 装饰器中设置 threads=N 参数。
更多使用可批处理 API 的 BentoML 示例:SentenceTransformers、CLIP 和 ColPali。
处理多个参数¶
可批处理的 API 端点除 bentoml.Context 外,只接受一个参数。对于多个参数,请使用复合输入类型,例如 Pydantic 模型,将这些参数分组到一个对象中。您还需要一个包装服务作为中间层来处理来自客户端的独立请求。
示例用法
from __future__ import annotations
from pathlib import Path
import bentoml
from pydantic import BaseModel
# Group together multiple parameters with pydantic
class BatchInput(BaseModel):
image: Path
threshold: float
# A primary BentoML Service with a batchable API
@bentoml.service
class ImageService:
@bentoml.api(batchable=True)
def predict(self, inputs: list[BatchInput]) -> list[Path]:
# Inference logic here using the image and threshold from each input
# For demonstration, return the image paths directly
return [input.image for input in inputs]
# A wrapper Service
@bentoml.service
class MyService:
batch = bentoml.depends(ImageService)
@bentoml.api
def generate(self, image: Path, threshold: float) -> Path:
result = self.batch.predict([BatchInput(image=image, threshold=threshold)])
return result[0]
在代码片段中
Pydantic 模型将所有必需的参数分组在一起。每个
BatchInput实例代表单个请求的参数,例如image和threshold。主要的 BentoML Service
ImageService有一个可批处理的 API 方法,用于接受BatchInput对象的列表。包装服务定义了一个 API
generate,用于接受单个请求的独立参数(image和threshold)。它使用bentoml.depends调用ImageService的可批处理predict方法,传入一个包含单个BatchInput实例的列表。
错误处理¶
如果 Service 处理请求不够快并超出 max_latency_ms,它将返回 HTTP 503 Service Unavailable 错误。要解决此问题,可以增加 max_latency_ms 或改善系统资源,例如增加内存或 CPU。